 SecurityArchitecture.com
SecurityArchitecture.com
European Court ruling invalidates Safe Harbor

The exchange of personal data between American and European organizations (commercial and government) has, since 2000, been managed under a “safe harbor” framework that allows entities in the United States to send personal data to or receive data from European Union member countries if the U.S. entities first certify their compliance with seven privacy principles (Notice, Choice, Onward Transfer, Security, Data Integrity, Access, and Enforcement). A recent legal proceeding before the European Court of Justice (ECJ) involves an Austrian Facebook user who complained to the Data Protection Commissioner in Ireland (home to Facebook’s European operations) that Facebook routinely transfers data on its European users to servers located in the United States. The Irish Data Protection Commissioner refused to investigate his complaint, due largely to the fact that Facebook’s practice fall under the jurisdiction of the safe harbor framework. The complainant argued to the ECJ that, in light of revelations by Edward Snowden about mass surveillance conducted by the National Security Agency, privacy protections asserted by U.S. companies could not be considered adequate. The European Court agreed, and invalidated the entire safe harbor framework.
The ECJ ruling is interesting from at least three perspectives. First, it is implicitly a declaration that, by permitting access to European citizens’ personal data by the NSA or other government agencies that most certainly do not adhere to core EC privacy principles like transparency, the U.S. violates the onward transfer principle and essentially negotiated the safe harbor framework in bad faith. Almost immediately after the ruling government and industry groups as well as privacy advocates speculated that the U.S. and EU would quickly seek to re-establish some sort of functionally equivalent arrangement, but it is hard to see how the EC will be willing to accept any new alternatives while the U.S. government is simultaneously seeking to increase information sharing from private sector companies to government agencies with the Cybersecurity Information Sharing Act (CISA). Second, the invalidation of the safe harbor framework presents real and immediate obstacles to business-as-usual for companies with significant global operations, particularly including multinational technology service providers like Microsoft, Amazon, Google, and Facebook. Third, the blunt assessment by the ECJ that U.S. data protections are inadequate should (but probably won’t) call into question the very different approach that the U.S. takes to protecting individual privacy.
Background
For at least 20 years, one key distinction between the United States and other developed countries (particularly including those in Europe) is in the relatively weaker personal privacy protections that exist among U.S. regulatory schemes compared to those in the European Community. Privacy laws and regulations in the U.S. largely share a common origin in a set of fair information principles issued in 1973 by what was then the U.S. Department of Health, Education, and Welfare. These principles – Openness, Individual Access, Individual Participation, Collection Limitation, Use Limitation, Disclosure Limitation, Information Management, and Accountability – were codified in the Privacy Act of 1973, which remains the primary privacy-centric legislation covering the actions of government agencies with respect to personal information about U.S. citizens.
Other U.S. legislation with industry or population-specific privacy implications includes the Health Insurance Portability and Accountability Act (HIPAA) and Health Information Technology for Economic and Clinical Health (HITECH) Act in the health sector, the Graham-Leach Bliley Act (GLBA) in banking, Family Educational Rights and Privacy Act (FERPA) in education, and Fair Trade Act, Fair Credit Reporting Act (FCRA), and Children’s Online Privacy Protection Act (COPPA) reflect these same principles and specify the circumstances under which organization are allowed to share or disclose personal information. In many cases, obtaining consent from individuals is required before such information sharing can occur.
A similar set of principles, articulated by the Organization for Economic Cooperation and Development (OECD), formed the basis of data privacy protection legislation enacted by every European Union country and for the EU-wide Directive 95/46/EC governing the protection of personal data. The European Directive, in contrast to essentially all U.S. regulations, starts from a presumption that personal information should not be shared at all unless certain conditions are met, chiefly among which are that any use of data should be transparent (including requiring individual consent), serve a legitimate purpose, and be limited in scope to meet the purpose for which data is collected and used. The EU regulations are also concerned with the sharing or transmission of personal data outside the EU member countries, requiring that to allow such transmission, adequate privacy protections must be in place in the country where the data is received. The European Council considers “adequate” to mean that protections are just as strong in third-party countries as they are in Europe. The U.S. privacy regulations have never really been considered adequate, but with significant business and government interests underlying a desire to allow data flows to and from Europe, the United States established the safe harbor framework that allowed U.S. companies to engage in information exchanges with EU entities if they make an attestation that they comply with EU data protection principles in the Directive. That process worked more or less as intended until October 6, when the European Court of Justice (ECJ) ruled that the safe harbor provision adopted by the EC in 2000 is “invalid.”
T-Mobile customers suffer breach because company relied on Experian

On October 1, T-Mobile announced a breach of personal information for as many as 15 million of its customers. Although the incident affected T-Mobile customers, the compromise of their personal data stemmed from an attack on a server maintained by credit reporting giant Experian. According to a press release from Experian about the incident, only T-Mobile customer credit reporting data was on the server that was the target of the attack. The implication from Experian is that there has been no impact on other IT infrastructure used to support similar credit reporting services for other customers or the extensive consumer data stores that Experian maintains for its core business operations. Despite those assertions, many outside observers (as well as T-Mobile customers) have called into question Experian’s overall security practices, especially in light of the fact that this is not the first breach from an Experian business unit. As security journalist Brian Krebs reported in July, a federal class action lawsuit filed in California claims that Experian violated the Fair Credit Reporting Act (among other regulations), citing the company’s negligence in failing to detect the illegal access to and resale of consumer records by one of the company’s customers, who pretended to be a private investigator but actually sold data retrieved from Experian to identity thieves.

In the wake of the breach announcement, a coalition of consumer privacy groups called on the government to launch a formal investigation into the T-Mobile incident as well as broader examination of Experian’s security to more conclusively determine whether any other databases or systems at Experian have been compromised or could be vulnerable to similar attacks. Consumer advocates have also made note of the sadly ironic offer by Experian to T-Mobile customers that they enroll in credit monitoring and identity resolution services provided by another Experian business unit (ProtectMyID). Even if true, the emphasis that Experian has placed on what it says is the limited scope of the incident – affecting only T-Mobile customer data and, ostensibly, only one server – raises legitimate questions about what attributes or protective measures of the IT used for T-Mobile are unique or significantly different from configuration settings and security controls used across Experian. Most large enterprises employ “standard” server hardware, operating system, and database images, whether they use physical or virtualized servers. On its face, it isn’t a credible argument that the configuration of the Experian server dedicated to T-Mobile customer data differs from others the company maintains, but perhaps the methods of access afforded to the T-Mobile database or points of integration between T-Mobile’s corporate systems and Experian were to blame for the successful attack.
The most pressing concern regarding Experian’s security effectiveness (or lack thereof) is, of course, the fact that the company, along with peer credit reporting agencies Equifax and TransUnion, maintain detailed consumer records on the vast majority of Americans. The sheer scale of the personal information stored by these companies means that any compromise of their security resulting in data breaches could have significant consequences for U.S. consumers. From the perspective of T-Mobile and other companies that rely on credit reporting services from third parties like Experian, this breach highlights the general insufficiency of any corporate security program that fails to carefully consider the risk exposure represented by trusted third parties given access to or custody of sensitive information.
Retiring an email server with sensitive data on it? Learn some lessons from Clinton

In the latest chapter in the ongoing saga concerning Hillary Clinton’s use of a private email server for herself and some of her staff during her tenure as Secretary of State, the Washington Post reported that the IT services company Clinton hired to manage the server after she left the State Department has “no knowledge of the server being wiped” despite suggestions by Clinton and her attorney that the contents of the server had been permanently erased. Much has been made of the important technical distinction between deleting files or data on a computer and wiping the hard drive or other storage on a computer. As many people aside from Clinton seem to be aware, merely deleting files does not actually erase or remove them, but simply makes the storage space they take up available to be overwritten in the future. Depending on the use of a computer afterward, deleted data can remain in storage and may be retrievable through simple “undelete” commands or through forensic analysis. In contrast, wiping is meant to permanently remove data from storage by overwriting the space it occupied with random data; data erasure methods used by many government and private sector entities overwrites the data multiple times to better ensure that the original data cannot be retrieved or pieced back together.
Those who have been following the historical accounts of the Clinton email server may recall that there have actually been two servers in use – the first was set up and maintained at the Clintons’ home in Chappaqua, New York, while the second was put into service when Clinton moved her email system management to Platte River Networks. (Historical analysis of DNS records associated with clintonemail.com suggest the switch to a third-party host may have occurred in 2010 rather than 2013). If tasks like server wiping were left to the Clinton team and not handled by Platte River, then it seems at least possible that the original server may not have been properly wiped when the data on it was transferred to the new server. According to Post reports, Platte River took possession of the original server and stored it at a data center facility in New Jersey until it handed the server over to the FBI at Clinton’s request. News accounts of the Platte River relationship explain that emails covering Clinton’s entire service as Secretary of State were on the original server and were migrated to a new server. The contents of the second server were subsequently copied to removable
media in 2014 and either deleted or removed from that server. The latest details suggest that neither of the two servers may have been wiped, but since they ostensibly contain the same data (at least from the 2009-2013 time period when Clinton was at State), if either server was not sanitized then many if not all of Clinton’s emails could be retrieved. Because the server and its data were migrated to a new server in 2013, there is little practical value in keeping the original server, especially if its contents had been securely erased. Clinton’s team should now feel some measure of relief that they did not dispose of the the original server if it turns out that is wasn’t wiped.
From a security best practice standpoint, if in fact the Clinton email server was not wiped as Clinton and her team apparently intended, then this failure to permanently remove Clinton’s personal emails and any other data she didn’t wish to share with government investigators provides another good example of operational security controls that would presumably be in place with a government-managed email server that were lacking in Clinton’s private setup. The National Institute of Standards and Technology (NIST) refers to data wiping by the more formal term “media sanitization” and requires the practice for all information contained in federal information systems, regardless of the sensitivity level of the data. While it is certainly likely that at least some public and private sector organizations fail to perform data wiping on servers, computer workstations, and other hardware that includes writeable storage, it is a very common security practice among organizational and individual computer users.
The possibility that Clinton’s email hasn’t been, as her attorney and spokespeople have asserted, completely removed from the server may make it a bit harder for her critics to argue that Clinton’s deliberate action to wipe the server is a sign that she has something to hide, although it may be that she and her staff intended to permanently remove the emails and just didn’t have the technical knowledge to do it properly. This is troubling in part because of the implication that – notwithstanding the security skills of the State Department staffer the Clintons privately paid to manage the server they kept at their home – routine security practices may not have been put in place. When the use of the private server became widely known, several sources used publicly available information about the clintonemail.com domain and the Microsoft Exchange server used to provide email services for Clinton and others. It’s hard to know whether even basic security recommendations from Microsoft were followed, but some have pointed to server and operating system fingerprinting results indicating the server was running Windows Server 2008 (and had not been upgraded to the more secure 2012 version). Aside from potential vulnerabilities associated with the OS and the Exchange 2010 software that may or may not have been patched, the server was also apparently configured to allow remote connections both via Outlook Web Access and an SSL VPN, both of which used self-signed digital certificates to establish secure connections. It makes sense that Clinton would want and need access to the server from anywhere, although a more secure approach would limit connections to Outlook email clients or ActiveSync-enabled devices. Regardless of how well (or poorly) the server was secured while it was operational, the steps taken to secure the data once the server was no longer in use provide a good example of what not to do.
Want to reduce unauthorized login attempts? Use Google Authenticator

If you have a public website, you should know that your site is regularly scanned and otherwise accessed, both by web “crawlers” from Google, Bing, and similar search engines and by individuals or agents with less benign intentions than cataloging your site’s pages. Websites running on popular platforms like WordPress or Joomla that expose their administrator and user login pages to public accessible with standards, predictable URL patterns are often targeted by intruders who attempt brute force login attacks to try to guess administrator passwords and gain access. There are many ways, on your own or through the use of available plugin applications, to keep these types of unauthorized attempts from being successful, but it is relatively difficult to prevent the attempts from occurring at all. The most effective methods for defending against brute force attacks and other types of unauthorized access attempts tend to focus on adding and configuring one or more .htaccess files to a website to control access to directories, files, and web server functionality. Many popular WordPress security plugins, for example, enable features that modify .htaccess files in combination with scripts that track the number of login attempts from an IP address or associated with a single username. This can provide login lockout functionality that both limits the number of failed attempts that can be made (thwarting brute force attacks) and prevents future access from IP addresses or agents that tried to log in.
 With restrictions in place like limiting the number of login attempts and blacklisting IP addresses or address ranges, a website administrator can be relatively confident than an unauthorized user will not be able to gain access (assuming of course that good passwords are also employed for authorized user accounts). It can nevertheless be very difficult to significantly reduce unauthorized login attempts, particularly when attackers use automated botnets or distributed attack tools to vary their source IP addresses. It may seem like an improvement a site only allows one failed attempt per IP address, but if an attack uses hundreds or thousands of source computers, the volume of failed attempts can still cause performance problems for a targeted site (not to mention filling up the administrator’s email inbox with failed login notices). One good way to eliminate a greater proportion of these attempts than is possible through IP blacklisting is to implement some type of two-factor authentication.
With restrictions in place like limiting the number of login attempts and blacklisting IP addresses or address ranges, a website administrator can be relatively confident than an unauthorized user will not be able to gain access (assuming of course that good passwords are also employed for authorized user accounts). It can nevertheless be very difficult to significantly reduce unauthorized login attempts, particularly when attackers use automated botnets or distributed attack tools to vary their source IP addresses. It may seem like an improvement a site only allows one failed attempt per IP address, but if an attack uses hundreds or thousands of source computers, the volume of failed attempts can still cause performance problems for a targeted site (not to mention filling up the administrator’s email inbox with failed login notices). One good way to eliminate a greater proportion of these attempts than is possible through IP blacklisting is to implement some type of two-factor authentication.  There are several commercial and open-source alternatives available, including Duo Security, OTP Auth, and Google Authenticator, all of which have PHP-based implementations available that make them suitable for use with WordPress and many other web server and content management platforms. All of these tools work in essentially the same way, where the website or application and its users run a pseudo-random number generator initiated with the same seed value (so the series of numbers they produce match). Adding this type of two-factor authentication (2FA) to a login page means users will need to enter their username, password, and one-time code generated by software on a device under their control (typically a computer workstation or smartphone).
There are several commercial and open-source alternatives available, including Duo Security, OTP Auth, and Google Authenticator, all of which have PHP-based implementations available that make them suitable for use with WordPress and many other web server and content management platforms. All of these tools work in essentially the same way, where the website or application and its users run a pseudo-random number generator initiated with the same seed value (so the series of numbers they produce match). Adding this type of two-factor authentication (2FA) to a login page means users will need to enter their username, password, and one-time code generated by software on a device under their control (typically a computer workstation or smartphone).
 This post discusses Google Authenticator as a representative example (the tool has apps for both Android and iOS devices, is used on Google sites and many third-party services, and can be added to WordPress sites via a free plugin). Setting up 2FA on a Google-enabled site entails generating a shared secret stored by Google Authenticator and the end user’s device. The smartphone apps allow users to scan a QR code or manually enter the secret, as shown below (note: neither the secret nor the QR code in the image are actual Google Authenticator settings).
This post discusses Google Authenticator as a representative example (the tool has apps for both Android and iOS devices, is used on Google sites and many third-party services, and can be added to WordPress sites via a free plugin). Setting up 2FA on a Google-enabled site entails generating a shared secret stored by Google Authenticator and the end user’s device. The smartphone apps allow users to scan a QR code or manually enter the secret, as shown below (note: neither the secret nor the QR code in the image are actual Google Authenticator settings).
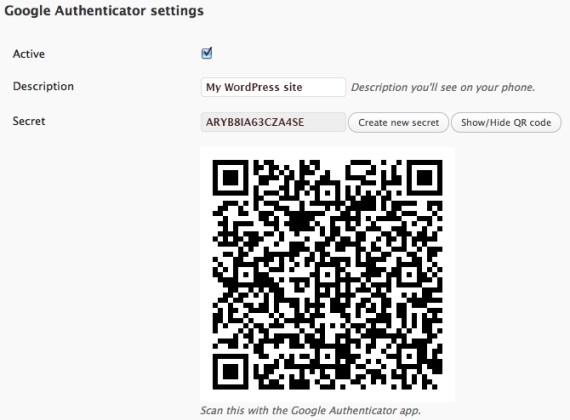 On WordPress sites, installing the Google Authenticator plugin modifies the login page to add a third field for the one-time code (which changes every 30 seconds). While no means a perfect solution, the way many automated probes and scripts seem to work, encountering a login page with an additional 2FA field prevents the submission of the login form or (depending on the specific tools) generates a form error separate from the failed login or HTTP 404 errors commonly associated with unauthorized access attempts.
On WordPress sites, installing the Google Authenticator plugin modifies the login page to add a third field for the one-time code (which changes every 30 seconds). While no means a perfect solution, the way many automated probes and scripts seem to work, encountering a login page with an additional 2FA field prevents the submission of the login form or (depending on the specific tools) generates a form error separate from the failed login or HTTP 404 errors commonly associated with unauthorized access attempts.
It’s (past) time for two-factor authentication

With the general unease about relying on usernames and passwords for authentication, conventional wisdom in information security seems to agree that organizations should add a second (or third, or fourth …) means of authentication is an obvious step to enhance security for systems, networks, and (especially) web applications. In an approach commonly termed strong authentication, two-factor authentication (2FA), or multi-factor authentication (MFA), the idea is to add “something you have” or, less often, “something you are” to the password-based credentials that are already “something you know.” There are certainly dangers to depending too much on authentication, no matter how strong, as a control to protect information assets, but industry and government seem to agree that two-factor authentication helps to address the threat posed by the compromise of user credentials – a cause cited in numerous high-profile breaches, including the ones at Anthem, Target, Home Depot, and the Office of Personnel Management (OPM).
In commercial domains, two-factor authentication is familiar to organizations subject to the Payment Card Industry Data Security Standards (PCI DSS), which requires merchants to use 2FA for remote network access. Major social media and online service providers now offer optional two-factor authentication to user accounts; these include Amazon Web Services, Apple, Dropbox, Facebook, Google, Microsoft, and Twitter. In some cases, including Apple, Dropbox and Twitter, making 2FA available to users was a direct result of user account compromises, data breaches, or exposure of related security vulnerabilities. While 2FA is by no means foolproof, for most users adding some form of two-step verification in the authentication process makes their accounts much less susceptible compromise to unauthorized users, even if they are tricked by a phishing email or other social engineering tactic.
Two-factor authentication is hardly a new concept, as requirements to use it in some industries and public sector systems date to at least 2005, when the Federal Financial Institutions Examination Council (FFIEC) first issued guidance to banks recommending two-factor authentication for online banking services and when the National Institute for Standards and Technology (NIST) released its first version of Special Publication 800-53, “Recommended Security Controls for Federal Information Systems.” At that time, NIST required multi-factor authentication (specifically, the control and its enhancements are under IA-2 within the Identification and Authentication family) only for federal agency systems categorized has “high impact” – a designation most often associated with critical infrastructure, key national assets, protection of human life, or major financial systems. The following year, when NIST first revised 800-53, it added multi-factor authentication as a requirement for “moderate impact” systems, but only for remote access. By 2009, Revision 3 of 800-53 extended multi-factor authentication as a requirement for network access to privileged accounts for all federal systems, and required MFA for non-privileged access to moderate- or high-impact systems.
Despite these long-standing requirements and a formal mandate in early 2011 from the Office of Management and Budget (OMB) directing federal agencies to implement strong authentication using personal identity verification (PIV) ID cards to complement usernames and passwords, many agencies have been slow to enable multi-factor authentication. In its annual report to Congress for fiscal year 2014, required under the Federal Information Security Management Act (FISMA), OMB reported an overall government implementation rate of 72 percent (up from 67 percent in 2013) for strong authentication. Several agencies, however, apparently made no progress at all in 2013 or 2014, and 16 agencies were called out for allowing “the majority of unprivileged users to log on with user ID and password alone, which makes unauthorized network access more likely as passwords are much easier to steal through either malicious software or social engineering.” Perhaps unsurprisingly, OPM is among these 16 agencies; OPM’s own Inspector General noted in the agency’s 2014 FISMA audit that although 95 percent of OPM user workstations required PIV-based authentication, none of the 47 major applications in OPM’s FISMA inventory require this type of strong authentication. Not mentioned in this report are access to systems by contractors, many of whom are not issued PIV cards and who must therefore use alternate MFA methods, assuming OPM or other agencies make such methods available.